Writing PySpark DataFrame to Google Cloud Storage on Databricks
Start your free 7-days trial now!
The first step is to create a service account on Google Cloud Platform (GCP) and download the private key (JSON file) for authentication. Please check out my guide to learn how to do so.
Uploading JSON credential file
After downloading the JSON credential file to your local machine, we will upload this file onto Databricks using the web Databricks notebook. Firstly, click on Upload Data:
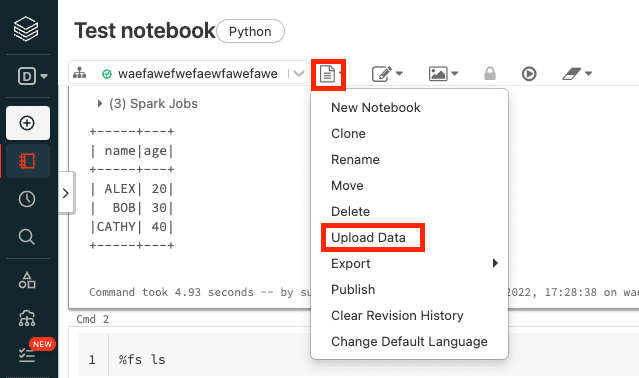
Technically speaking, we are uploading a JSON file and not a dataset (e.g. CSV), but this still works regardless.
Next, select the private key (JSON file) and then click on Next:
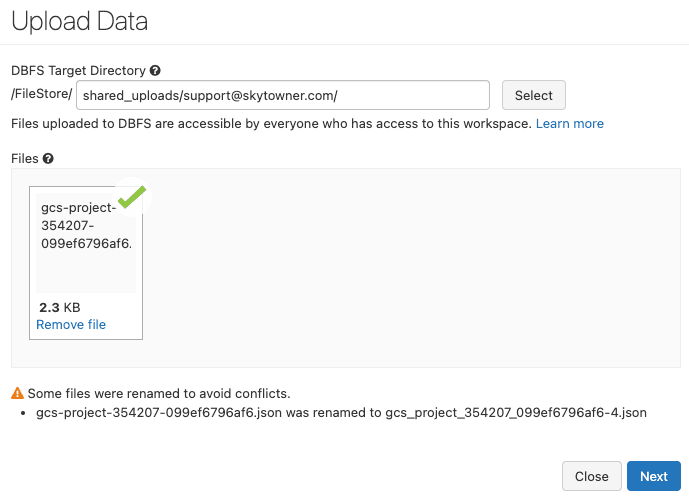
Next, copy the file path in Spark API Format:
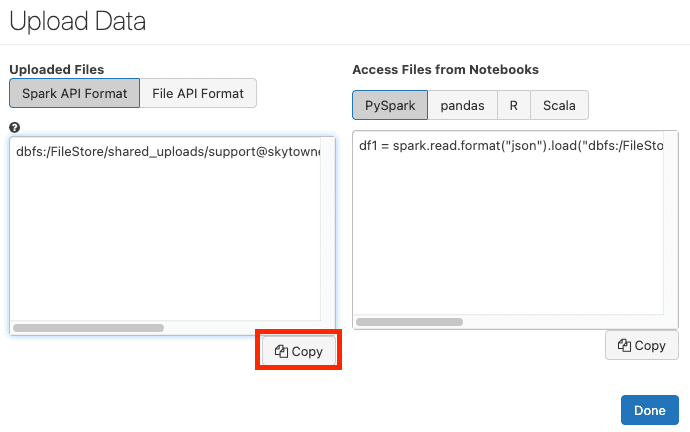
After pressing Done, our JSON file will be stored in the Databricks' file system (dbfs) and is accessible in the copied dbfs path.
Copying the file from DBFS to local file system in the driver node
However, the catch is that Python methods cannot directly access files stored in dbfs, so we must use the Databricks built-in method dbutils.fs.cp(~) to copy this file from dbfs to the standard local file system on the driver node (say the tmp folder in the root directory):
dbfs_path = 'dbfs:/FileStore/shared_uploads/support@skytowner.com/gcs_project_354207_099ef6796af6-3.json'new_local_path = 'file:///tmp/gcs_project_354207_099ef6796af6-3.json'dbutils.fs.cp(dbfs_path, new_local_path)
True
To confirm that our file has been written to the tmp folder in the driver node, write the following command in Databricks notebook cell:
ls /tmp
...gcs_project_354207_099ef6796af6-3.json...
We should see our private key.
Writing PySpark DataFrame as a CSV file on Google Cloud Storage
Since Databricks does not come with the GCS Python client library google-cloud-storage installed, we must use pip to install this library:
pip install --upgrade google-cloud-storage
Note that we run this command directly in the Databricks notebook.
Now suppose the PySpark DataFrame we wish to write to GCS is as follows:
+-----+---+| name|age|+-----+---+| Alex| 20|| Bob| 30||Cathy| 40|+-----+---+
To write this PySpark DataFrame as a CSV file on GCS, we can use the DataFrame's toPandas() method to first convert the PySpark DataFrame into a Pandas DataFrame, and then use the to_csv() method to convert the Pandas DataFrame into a CSV string:
from google.cloud import storage
# The path to our JSON credential filepath_to_private_key = '/tmp/gcs_project_354207_099ef6796af6-3.json'client = storage.Client.from_service_account_json(json_credentials_path=path_to_private_key)
# The bucket in which to store the CSV filebucket = storage.Bucket(client, 'example-bucket-skytowner')# The name assigned to the file on GCSblob = bucket.blob('my_data.csv')
Note that df.toPandas().to_csv() returns the following CSV string:
All of the PySpark DataFrame data, which is typically spread across multiple worker nodes, will be sent to the driver node and concatenated to form a Pandas DataFrame when calling toPandas(). Therefore, if there is not enough memory allocated to the driver node, then a OutOfMemory error will be thrown.
After running our code, we can confirm that our CSV file has indeed been created on the GCS web console:
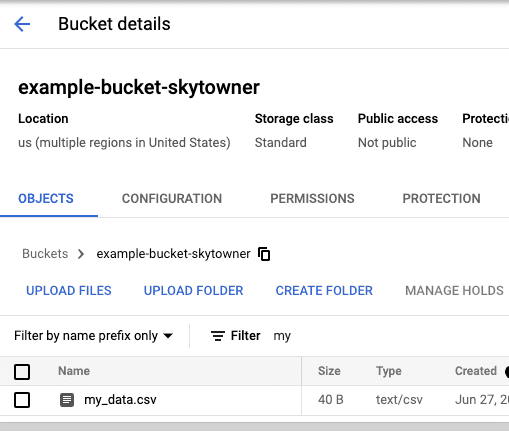
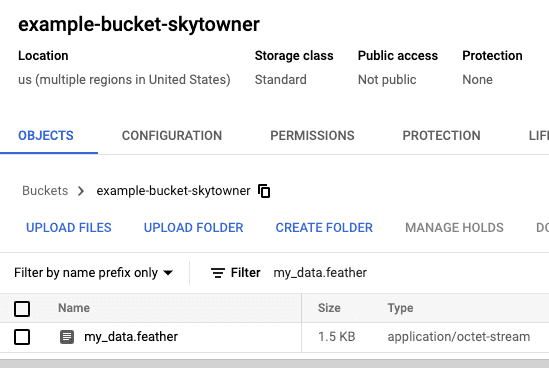
Writing PySpark DataFrame as a Feather file on Google Cloud Storage
The logic to write a PySpark DataFrame as a feather file on GCS is very similar to the CSV case:
import pyarrow.feather as feather
# The bucket in which to place the feather file on GCSbucket = storage.Bucket(client, 'example-bucket-skytowner')# The name to assign to the feather file on GCSblob = bucket.blob('my_data.feather')blob.upload_from_filename('/tmp/feather_df')
Here, note the following:
once again we are converting the PySpark DataFrame into a Pandas DataFrame.
we use the
feathermodule, which is pre-installed on Databricks, and write the Pandas DataFrame as a feather file in the local file system on the driver node.we then use the blob's
upload_from_filename(~)method to upload this feather file onto GCS
After running this code, we should see our feather file on the GCS web console: