

Normal Distribution
Start your free 7-days trial now!
Google Colab
Click here to see the Python code used for this guide!
What is the normal distribution?
The normal distribution, or sometimes referred to as the Gaussian distribution, is by far the most common probability distribution that occurs in nature. The normal distribution is also called the bell curve in layman terms because the graph of the distribution looks like bell:
Many variables in nature follow the normal distribution. For instance, the frequency histogram of some population's height will more or less resemble the shape of the normal distribution. Exam and IQ scores also typically follow the normal distribution.
The normal distribution has a myriad of useful statistical properties that make this distribution easy to work with. In this guide, we will dive into the rigorous mathematics behind the normal distribution!
Probability density function
A random variable $X$ is said to follow a normal probability distribution if the density function of $X$ is:
For the bounds $-\infty\lt{x}\lt\infty$.
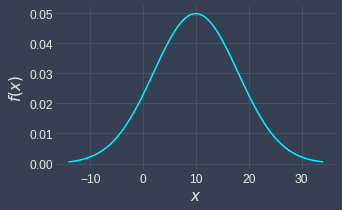
The following is a graph of the normal probability density function with mean $\mu=10$ and variance $\sigma^2=4$:
Notice how the peak of the curve occurs at the $\mu$.
Effect of variance on the shape of probability density function
The variance parameter controls the width of the bell curve. The higher the variance, the wider the bell curve becomes.
We prove this claim by plotting 3 normal distributions with the same mean but different variance:
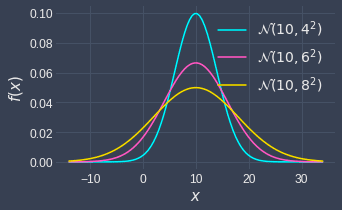
Notice how the distribution with the highest variance is widest.
Mean and variance
A normal random variable $X\sim{\mathcal{N}(x;\mu_X,\sigma_X^2)}$ has a mean and variance of:
Proof. Recall that the normal probability density function is:
Notice how we've actually denoted the parameters as $\mu_X$ and $\sigma^2_X$, which implies that they represent the mean and variance of the normal random variable $X$. We're now going to prove that they are in fact so.
We first begin with the proof of the mean. Typically, we would compute $\mathbb{E}(X)$ directly to obtain the mean. However, as you will see shortly, computing $\mathbb{E}(X-\mu_X)$ instead would result in a more elegant and concise proof.
We begin with the definition of expected values:
We now a define a new variable $z$ as follows:
Substituting z into z gives:
The critical observation to make here is that the integral is an odd function, that is, $f(-x)=-f(x)$. This means that the function is symmetric to the $y$-coordinate. Since the bound of integration is also symmetric, the integral would simply equal to $0$. Therefore:
The completes the first part of the proof that the mean of $X$ is simply $\mu_X$.
Let's now move on to computing the variance of $X$. Our plan of attack is to rewrite $X$ in terms of $Z$ to take advantage of the fact that the variance of a random variable following a standard normal distribution is 1 (i.e. $V(Z)=1$). The proof is somewhat straight forward:
The first line holds true as the Z-transformation is defined as follows:
The second and third lines use the basic properties of variance. The final line comes from the fact that $\mathbb{V}(Z)=1$.
This completes the second part of the proof that the variance of X is simply $\sigma_X^2=\sigma_X^2$.
Moment generating function
A normal random variable $X\sim{\mathcal{N}(x;\mu_X,\sigma_X^2)}$ has the following moment generating function:
Proof.
Let's focus on the exponent component:
Let us now focus on the numerator:
Therefore, the entire exponent term is:
The red component does not depend on x, so let's extract that part out to give:
This part will be put outside the integral, since it is a constant (i.e. not containing the variable x). Let us focus on the rest:
So, the entire integral component is follows:
Notice how this is an equation of a normal distribution with mean $\mu_X+\sigma^2_Xt$ and variance $\sigma_X$. Since the area under the curve for a probability density function is equal to zero, we have that:
Now, what remains is the non-integral component \eqref{eq:VhZHxTku0bTMM1rmjCa}:
Reproductive property
Let $X_1$ and $X_2$ be two independent random variables both having normal distributions. However, note that they are not i.i.d., that is, although they are independent and both have normal distributions, they are not identically distributed since the value of the parameters can be different.
The random variable $Y=a_1X_1+a_2X_2$ is also normally distributed with the following parameters:
Proof. When combining two random variables which are both normally distributed, the result will also be a random variable that is normally distributed. The new mean will simply be the sum of the two-means added up together (i.e. note that each mean is multiplied by the constant term). The new variance will simply be the sum of the two added up as well, but we also need to square the constant term in front. This is why we never get a negative term for variances.
Let the normal distribution of $X_1$ have mean $\mu_1$ and variance $\sigma_1^2$ and $X_2$ have mean $\mu_2$ and variance $\sigma_2^2$. Let random variable $Y$ be defined by the linear combination of $X_1$ and $X_2$, that is, $Y=a_1X_1+a_2X_2$. Our first task is to prove that $Y$ is normally distributed. We can use the concept of moment generating functions to cleverly show this.
As proven in theoremlink, the moment generating function of the normal distribution is:
From theorem , we know that:
Now using theorem,
Notice that this is the moment-generating function of a normal distribution with mean $a_1\mu_{X_1}+a_2\mu_{X_2}$ and variance $a_1^2\sigma_{X_1}^2+a_2^2\sigma_{X_2}^2$. By the unique theorem of moment-generating function, we can deduce that $Y$ is normally distributed with the above mean and variance, that is:
Note that, we go could have done the following to determine the expected value as well as the variance of $Y$. However, this does not tell you that that $Y$ is normally distributed, and so lacks mathematical strength to prove our miraculous theorem.
Great, let’s focus on the variance now. We know that $X_1$ and $X_2$ are independent, and so we can say the following:
Notice how we obtained the same expected value and variance of $Y$ as in our theorem.
Maximum likelihood estimation
Suppose $X_1$, $X_2$, ..., $X_n$ are independent and identically distributed random samples drawn from a normal distribution with mean $\mu$ and variance $\sigma^2$. The maximum likelihood estimates of $\mu$ and $\sigma^2$ are:
Here, $\bar{x}$ is the sample mean. Notice how the $\sigma^2_{\mathrm{MLE}}$ is a biased estimator since we are dividing by $n$ instead of by $n-1$.
Proof. Suppose that a random sample $x_1$, $x_2$, ..., $x_n$ is taken from a normal distribution. The likelihood equation is given by:
Taking natural logarithm gives:
Since we have two unknown parameters $\mu$ and $\sigma^2$, we must use partial differentiation:
Now we take the partial derivative with respect to $\sigma^2$. This can be slightly confusing because we are taking a derivative with respect to a squared term, so I recommend setting $k=\sigma^2$:
Now all we need to do is set the partial derivatives equal to zero. We will end up with two simultaneous equations with two unknowns $μ$ and $\sigma^2$:
From the first equation, we know the following:
Now that we have the value of $\mu$, we can simply substitute this into the second equation and solve for $k$:
Notice $\bar{x}$ is an unbiased estimator for μ. However, $\sigma^2$ is a biased estimator for $\sigma^2$ since we already know from the past that the following is an unbiased estimator for $\sigma^2$:
This example demonstrates that the MLE is not necessary an unbiased estimator! In fact, these are competing estimators (i.e. one is unbiased, while the other is MLE but biased).
Linear transformation of normal random variables
Suppose we have a normal random variable $X\sim\mathcal{N}(x;\mu_X,\sigma_X)$. Let the transformation be $Y=aX+b$ where $a$ and $b$ are constants. Then the following is true:
Proof. Suppose that $X\sim\mathcal{N}(x;\mu_X,\sigma_X)$. The neat aspect about this computation is that it does not matter whether $a\gt0$ or $a\lt0$. This is only true because there is a square term, and so any negative number becomes a positive at the end.
The Jacobian is:
The probability density function of $Y$ would therefore be:
Notice this is the probability density function of a normal distribution with mean $a\mu_X+b$ and standard deviation $\vert{a}\vert\sigma_X$ or variance $\mathbb{V}(Y)=a^2\sigma_X^2$, that is:
Standard normal distribution
The standard normal distribution is a special case of the normal distribution where:
parameter mean is 0.
parameter variance is 1.
The probability density function is:
Where the bounds are $x\in[-\infty,+\infty]$.
Recall that the normal probability density function is given by:
The standard normal distribution has a mean 0 and variance 1, that is:
Substituting this into the normal probability density function gives:
The standard normal distribution looks like the below:
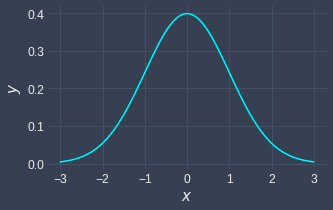
We can see that the standard normal distribution:
still takes on bell-curve shape
centered around $x=0$.
Other properties of the normal distribution
In this supplementary section, we will cover other mathematical properties of the normal distribution that we think are elegant but slightly less practical than those covered above. I recommend this section only to those who want to:
develop their mathematics skills
appreciate the elegance of the normal distribution 🌟
Area of probability density function is equal to one
As do all valid probability density functions, the normal probability density function has an area of 1, that is:
Proof. Let's start by putting the constant term outside of the integral:
We define a new variable $z$ defined like so:
In order to write the integrand in terms of $z$, we need to compute $dz$:
We also need to compute the bounds of the integral in terms of $z$. This is simple because from \eqref{eq:z0c2rTD8pgsc3dN9Z5a}, we can see that the bounds of $z$ would be $-\infty$ to $\infty$ as well.
With \eqref{eq:z0c2rTD8pgsc3dN9Z5a} and \eqref{eq:R3mYla1ynLDERgA2HRM}, we can rewrite \eqref{eq:ELDg8XRgbGPGRhzG028}:
Now, we need to refer to the famous Gaussian integral that we've proven previously:
Notice how \eqref{eq:OTNtchI4gu9dJLlf4XW} is very similar to \eqref{eq:kh95eOEBmXamFQsfCrD} except that the exponent in \eqref{eq:kh95eOEBmXamFQsfCrD} is halved. In order to make them aligned, we must perform another substitution:
Suppose $y$ is positive:
Once again, we need to compute $dz$ to perform substitution:
From \eqref{eq:b9vNpDEmxy4GJdEMofa}, we know that the bounds of $y$ would also be $-\infty$ to $\infty$.
Substituting \eqref{eq:lS0OWj1mfHlEgdMYnug} and \eqref{eq:qUAG9bHq5R0hD4kYGnz} into \eqref{eq:kh95eOEBmXamFQsfCrD} gives:
Now, using the Gaussian integral \eqref{eq:OTNtchI4gu9dJLlf4XW}, we have that:
Now, we have previously assumed $y$ to be positive in \eqref{eq:lS0OWj1mfHlEgdMYnug}. We also need to need to check for the case when $y$ is negative:
To obtain $dz$:
From \eqref{eq:NYShjb5GYU5ybyZO6AC}, we know that the bounds of y would be from $\infty$ to $-\infty$, which is the reverse of the positive case.
Substituting \eqref{eq:NYShjb5GYU5ybyZO6AC} and \eqref{eq:e1pmiyB37PQQI6Uhd7V} into \eqref{eq:kh95eOEBmXamFQsfCrD} gives:
Here, we have flipped the bounds, which means that the we need to multiple the integral by $-1$. What we have now is exactly the same as \eqref{eq:GzE4AtdbcB9jlnpx5qU}, and therefore would result in equalling $1$.