

Comprehensive Guide on Sample Correlation
Start your free 7-days trial now!
The prerequisites of this guide are as follows:
sample variance.
sample covariance.
Sample correlation coefficient
Suppose we have two samples $\boldsymbol{x}$ and $\boldsymbol{y}$, each of size $n$. The sample correlation coefficient $r_{xy}$ is computed as:
Where:
$s_{xy}$ is the sample covariance of $\boldsymbol{x}$ and $\boldsymbol{y}$.
$s_x$ and $s_y$ are the sample variance of $\boldsymbol{x}$ and $\boldsymbol{y}$ respectively.
Note that the sample correlation coefficient is sometimes referred to as:
correlation
sample correlation
Pearson product-moment correlation coefficient (PPMCC)
Pearson's correlation coefficient
Pearson’s r
Intuition behind sample correlation
Recall that the sample covariance measures the association between two variables:
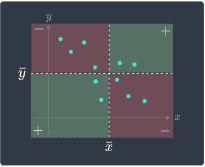
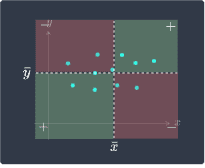
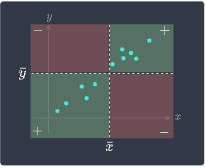
Negative covariance (as $x$ increases, $y$ decreases) | Zero covariance (as $x$ increases, $y$ fluctuates) | Positive covariance (as $x$ increases, $y$ increases) |
|---|---|---|
| 
| 
|
For a detailed explanation and intuition behind this diagram, please consult our guide on sample covariance. The problem with covariance is that covariance is largely affected by the scale of the samples, and so a high covariance does not necessarily mean that two variables have a strong positive association.
The sample correlation rectifies this issue by dividing the covariance by the standard deviation of the $X$ and $Y$. As we will prove later, this division normalizes the covariance such that it becomes bounded between $-1$ and $1$.
Here's how to interpret correlation:
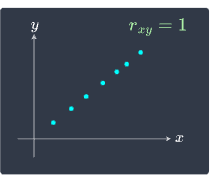
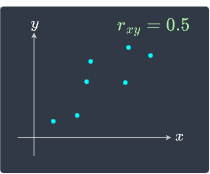
a correlation close to $1$: there is a strong positive association between the two variables. As $x$ increases, $y$ also tends to increase. We say that there is a strong positive linear relationship between $x$ and $y$.
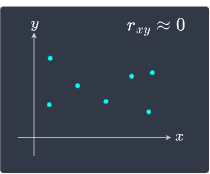
a correlation close to $0$: no association between the two variables. This means that $y$ does not change linearly with $x$.
a correlation close to $-1$: there is a strong negative association between the two variables. As $x$ increases, $y$ tends to decrease. We say that there is a strong negative linear relationship between $x$ and $y$.
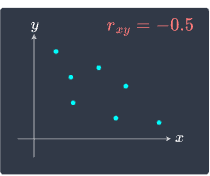
We illustrate these cases below:
| 
| 
|
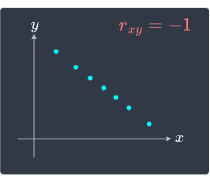
| 
| 
|
Notice how when $x$ and $y$ have a non-linear relationship as in the bottom-right scenario, the correlation is near zero.
Another equation for sample correlation
The sample correlation $r_{xy}$ can also be computed as:
Where:
$\bar{x}$ and $\bar{y}$ are the sample mean of $\boldsymbol{x}$ and $\boldsymbol{y}$ respectively.
$n$ is the sample size.
Proof. Recall that the formal definition of sample correlation is:
Where $s_{xy}$ is the sample covariance of $x$ and $y$, and $s_x$ and $s_y$ are the sample variance of $\boldsymbol{x}$ and $y$ respectively. Recall that sample covariance is computed as:
Whereas the sample variances $s_x$ and $s_y$ are computed by:
Substituting $s_{xy}$, $s_x$ and $s_y$ into the formula for sample correlation \eqref{eq:WsfZVDjiZARHz0YGJUN} results in:
This completes the proof.
Computing the sample correlation by hand
Suppose we have the following dataset:
$x$ | $y$ |
|---|---|
2 | 3 |
3 | 5 |
5 | 8 |
6 | 12 |
Compute the sample correlation of $\boldsymbol{x}$ and $\boldsymbol{y}$.
Solution. Let's use the formal definition to compute the correlation coefficient:
We first need to compute the sample means $\bar{x}$ and $\bar{y}$, which are required when computing the variance and covariance:
In our example, $n=4$. The sample means are as follows:
The covariance $s_{xy}$ of $\boldsymbol{x}$ and $\boldsymbol{y}$ is:
Here, we're just leaving $21/3$ as a fraction since the $3$ will cancel out later.
The variance $s_x$ is:
The variance $s_y$ is:
Putting this all together:
Because the correlation coefficient is close to $1$, we conclude that $\boldsymbol{x}$ and $\boldsymbol{y}$ are positively and strongly correlated. Let's confirm this visually:
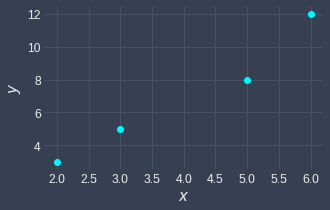
Indeed, we can see that as $x$ increases, $y$ tends to increase as well.
Computing sample correlation using Python
We can easily compute sample correlation by using Python's numpy library:
array([[1. , 0.97913005], [0.97913005, 1. ]])
Here, the x and y are the same values we used for the previous example. NumPy's corrcoef(~) method returns a symmetric correlation matrix whose diagonals are always 1. To extract the sample correlation, we use NumPy's [~] syntax:
corr_matrix[0][1]
0.9791300486523296
This is roughly equal to the sample correlation we computed by hand!