

Exporting PySpark DataFrame as CSV file on Databricks
Start your free 7-days trial now!
Consider the following PySpark DataFrame:
+-----+---+| name|age|+-----+---+| Alex| 20|| Bob| 30||Cathy| 40|+-----+---+
To write the PySpark DataFrame as a CSV file on the machine used by Databricks:
Here, note the following:
coalesce(1)means that we want to reduce the number of partitions of our data to 1, that is, we want to collect all our data which is initially scattered across multiple worker nodes into a single worker node.dbfsstands for Databricks file system.header=Trueincludes the column labels (nameandagein this case).
Now, the tricky part is downloading the CSV that now resides on the Databricks instance machine. Our goal is to obtain a download URL for this CSV file. The first step is to fetch the name of the CSV file that is automatically generated by navigating through the Databricks GUI. First, click on Data on the left side bar and then click on Create Table:
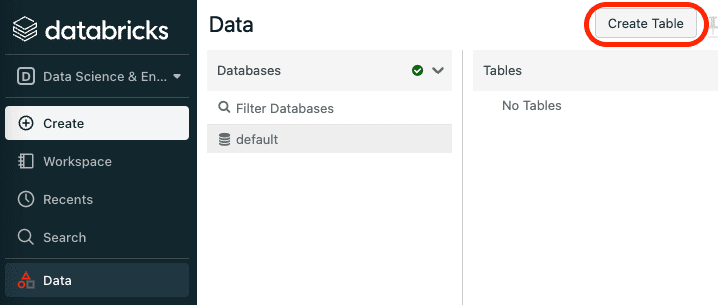
Next, click on the DBFS tab, and then locate the CSV file:
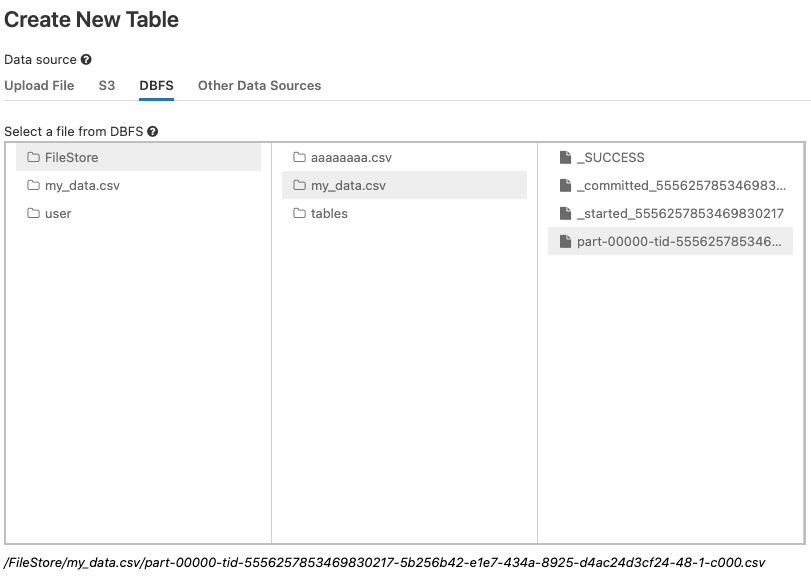
Here, the actual CSV file is not my_data.csv, but rather the file that begins with the part-.
Once you click on the part- file, you can see the path to this CSV file at the bottom. Copy everything after the /FileStore, so in my case, I would need to copy:
my_data.csv/part-00000-tid-5556257853469830217-5b256b42-e1e7-434a-8925-d4ac24d3cf24-48-1-c000.csv
Download link when using the community edition of Databricks
If you are using Databricks on the Community edition, then the download URL would be in the following form:
https://community.cloud.databricks.com/files/***
Here, you must replace the *** with the CSV file name obtained in the previous section:
https://community.cloud.databricks.com/files/my_data.csv/part-00000-tid-5556257853469830217-5b256b42-e1e7-434a-8925-d4ac24d3cf24-48-1-c000.csv
Finally, copy and paste this link on the URL bar in your browser and the CSV file should start downloading!
Download link when using Databricks hosted on cloud providers (Azure, AWS or GCP)
If you are using the paid version of Databricks that is hosted on some cloud provider, then the download URL would take on the following form:
https://<YOUR_DATABRICKS_INSTANCE_NAME>/files/***
Again, you would need to replace the *** with the CSV file name obtained above:
https://westeurope.azuredatabricks.net/files/my_data.csv/part-00000-tid-5556257853469830217-5b256b42-e1e7-434a-8925-d4ac24d3cf24-48-1-c000.csv