

Guide on Code Locations in Dagster
Start your free 7-days trial now!
What is a code location?
Code location is a file or directory that contains an instance of Dagster's Definitions, which specifies all the Dagster entities (e.g. assets, resources, schedules) required by our data pipeline. In a single deployment, we can have multiple code locations like so:
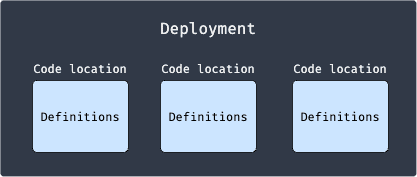
Note the following:
only a single
Definitionsobject is allowed for every code location - having multipleDefinitionsin one code location will throw an error.the
Definitionsobject must be available as a top-level variable. We'll explore more about this below.
Creating a code location using a module
Let's start by creating a minimal code location in our local machine. Create a folder called my_dagster_code_location and two Python files within it:
my_dagster_code_location├── __init__.py└── my_assets.py
The content of my_assets.py is as follows:
from dagster import assetimport pandas as pd
@asset(name="iris_data")def get_iris_data():
The content of __init__.py is as follows:
from dagster import Definitions, load_assets_from_modulesfrom . import my_assets
all_assets = load_assets_from_modules([my_assets])defs = Definitions(assets=all_assets)
Note the following:
we have a
Definitionsobject defined as a top-level variable - otherwise, Dagster will not be able to find our definitions and throw an error.the name assigned to the
Definitionsobject (defsin this case) is irrelevant, that is, we can assign any variable name we wish.
Let's now launch the Dagster UI and load our my_dagster_code_location as a module (-m) like so:
dagster dev -m my_dagster_code_location
Dagster will then look into the root __init__.py file within the my_dagster_code_location directory and load the Definitions object.
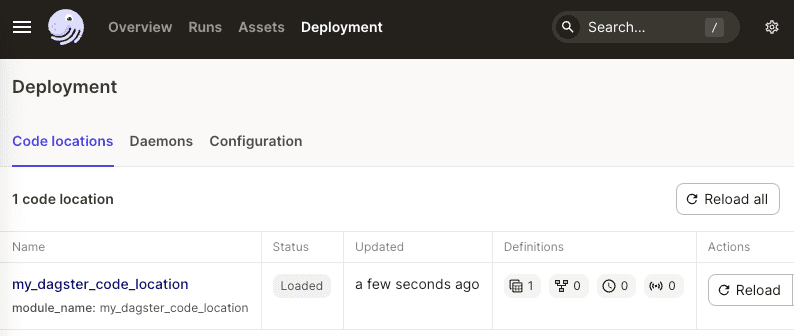
In the Dagster UI, click on Deployment in the header and we will be able to see our code location:
In Python, if-else statements have a more "global" scope compared to functions and classes. For instance, the following Definitions object is still considered to be in the top-level scope:
if True: defs = Definitions(resources={ "assets": my_assets })
However, we should not place the Definitions object inside functions or classes because it will no longer be at the top-level scope. The dagster dev command will still run without any error but it will not be able to know about all our Dagster entities.
Creating a code location using a file
Typically, a code location will be a module, but we could also use a file instead. To demonstrate, suppose we have a main.py file with the following content:
from dagster import Definitions, asset
@asset(name="empty_data")def get_empty_data(): return
defs = Definitions(assets=[get_empty_data])
We can then load this file as our code location like so:
dagster dev -f main.py
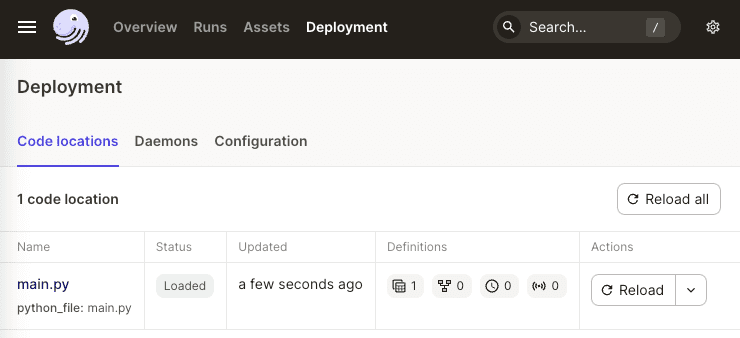
In Dagster UI, we see that the main.py is our code location:
Whether we go with the module or file code location approach, what's important is for Dagster to find the Definitions object.
Creating multiple code locations
Each Dagster deployment can have multiple code locations. For instance, consider the following two module code locations:
.venvmy_dagster_code_location└── __init__.pymy_other_dagster_code_location└── __init__.py
We can load both code locations by specifying multiple -m flags:
dagster dev -m my_dagster_code_location -m my_other_code_location
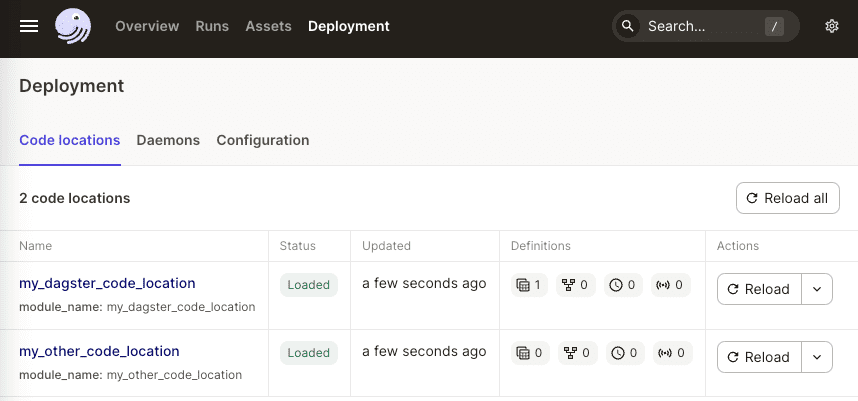
In the Dagster UI, we should now see two code locations:
We could also load multiple file code locations by using multiple -f flags.
How does Dagster interact with code locations?
By default, Dagster will launch a new process for each code location. This means that if we have 3 code locations, we would have 3 processes running like so:
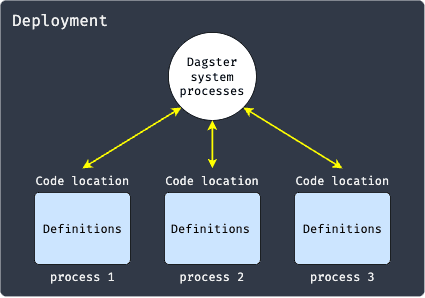
The Dagster system processes will communicate with these processes via RPC. This setup has two advantages:
each of the code location processes is independent, which is useful because this allows each code location to have its own environment. For instance, one code location can run using Python 3.8 with packages A and B, while another code location can run using Python 3.9 with packages A and C.
since the Dagster system processes run independently of code location processes, errors in user code will not crash the Dagster system processes.
Workspace files
A workspace file is a yaml file that indicates where the code locations can be found. In our previous minimal setup, we had to specify the relative path to the code locations using -m and -f flags when launching Dagster like so:
dagster dev -m my_dagster_code_locationdagster dev -f main.py
We can avoid specifying the flags by creating a workspace.yaml file that holds information about the path of the code locations. Command-line Dagster tools such as dagster dev, dagster-webserver and dagster-daemon run will use this workspace.yaml file during launch.
For instance, suppose we have the following file structure:
workspace.yamlmy_dagster_code_location└── __init__.py
Where our workspace.yaml file is:
load_from: - python_module: my_dagster_code_location
We can now launch our Dagster processes without the -m flag:
dagster dev
...2023-07-16 19:30:24 +0800 - dagit - INFO - Serving dagit on http://127.0.0.1:3000 in process 22682
Here, the workspace.yaml must be in the current directory for this to work. In the case when the workspace.yaml file is located elsewhere, we can use the -w flag to specify its path:
dagster dev -w path/to/workspace.yaml
As expected, we have the file code location version as well:
load_from: - python_file: my_file.py
We can also load multiple code locations by adding more entries like so:
load_from: - python_module: my_dagster_code_location - python_module: my_other_code_location
Hosting our own GRPC server
Code locations do not necessarily have to reside in the same node as the Dagster processes. Let's spin up another server that contains a code location:
dagster api grpc --module-name my_dagster_code_location --host 0.0.0.0 --port 4500
2023-07-16 19:48:25 +0800 - dagster.code_server - INFO - Started Dagster code server for module my_dagster_code_location on port 4500 in process 23246
Now, we have a so-called code location server running at localhost:4500. In our workspace.yaml file, we can indicate the location of this code location server like so:
load_from: - grpc_server: host: localhost port: 4500 location_name: "my_grpc_server"
Here, the location_name is the code location name you wish to assign - we will later see this name in the Dagster UI.
Open up another terminal and let's launch the Dagster server:
dagster dev
This command will read our workspace.yaml file and connect to the grpc server that we just defined.
Navigate to Deployment and observe how Dagster has identified our my_grpc_server as a code location server:
When we materialize the assets within our my_grpc_server code location, that code location server will execute our user code. We can confirm this by observing that the Dagster event logs appear in the grpc server when materializing an asset:
dagster api grpc --module-name my_dagster_code_location --host 0.0.0.0 --port 4500
...2023-07-19 22:38:30 +0800 - dagster - DEBUG - __ASSET_JOB - 0208971d-de32-4d43-9913-387f329d1080 - 71718 - RUN_START - Started execution of run for "__ASSET_JOB".2023-07-19 22:38:30 +0800 - dagster - DEBUG - __ASSET_JOB - 0208971d-de32-4d43-9913-387f329d1080 - 71718 - ENGINE_EVENT - Executing steps using multiprocess executor: parent process (pid: 71718)2023-07-19 22:38:30 +0800 - dagster - DEBUG - __ASSET_JOB - 0208971d-de32-4d43-9913-387f329d1080 - 71718 - iris_data - STEP_WORKER_STARTING - Launching subprocess for "iris_data".
This example is quite arbitrary because the code location server is hosted on the same machine. In practice, we would typically set up the grpc server in a remote machine (e.g. virtual machines) equipped with the suitable specs to handle code execution.